Bibliographic/Database
Contents
Introduction
The whole question of the need for a SQL database as part of the OpenOffice Bibliographic component is being actively debated. There are some good arguments for not having one. see the discussion in the dev list archive. David Wilson 08:53, 17 July 2006 (CEST)
Background
Biographic databases are used to store collections of bibliographic records. Many traditional bibliographic databases contained fields to store information about a limited range of printed works, books, articles, manuscripts etc. An example of this type database is BibTex which is used with the LaTex word-processing application. Many of the current bibliographic database are derived from that early and pioneering application. As new media types were developed new fields were added to the older databases structures, such as URL's for web addresses. Also a miscellaneous reference type was added to support all the other types of media now available, video, graphics etc.
The current OpenOffice bibliographic database is of that type. See OOo documentation for bibliodatafield for a list of the fields supported in that database. This database is a simple single table database. A limitation of this type of database is that it makes it very difficult or impossible to maintain information about the relationships between works and their parts and the contributors to the works. An example is relating author to their works. In a single table database, like the current bibliographic database, to search for the works that an author has been involved with requires the text-string searching of the author text-fields, and for this to work the user would have had to accurately enter the author's name in the exactly the same format for every work. The benefits of a separate author table where the author's name has to entered only once and then linked to the works of that author is clear. However, as there are often several people and organizations associated with a published work: authors, editors, publishers, authors of parts of the work, sponsors, series editors etc. it is often better to define relationships in the database than have long lists of the fields in a database table to cover every possibility, most of which would not be not used in any one record. This approach of defining the relationships through the database makes the database more flexible and preserves the actual relationships, at the cost of a more complex database and increased coding complexity. A cost we believe worth incurring.
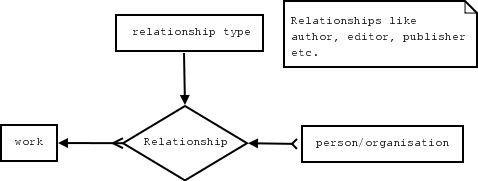
Database Design Objectives
- reliably import legacy formats such as RIS, Refer and BibTeX
- provide a more general data model that supports a wider range of citation needs (humanities, law)
- a broader range of reference types (video, audio, graphics, maps, etc.)
- reflect increasing use of electronic and online sources
- more complex relations (a paper presented at a conference and then published on the web, a book translated from an original, a revised book with an additional new introduction, etc.)
- should facilitate productivity enhancements such as auto-completing text fields for author and publisher names, and linking periodical abbreviated / short names to their full names and descriptions.
The last requirement, of course, explains why it's important to normalize so much of the structure (separate tables for collections, agents etc.).
The enhanced bibliographic database: OOo-BiblioDB
In designing the bibliographic database two models have been useful.
The first, the USA Library of Congress "Metadata Object Description Schema" (MODS) which supports modern library cataloging requirements using an XML schema, "it is intended to be able to carry selected data from existing MARC 21 records as well as to enable the creation of original resource description records". We found this model did not adequately define the structure of the reference material that we were dealing with.
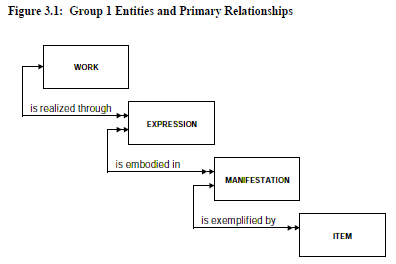
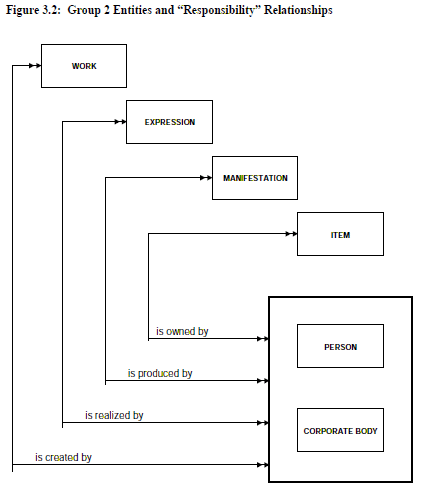
The second model, described in the 'Functional Requirements for Bibliographic Records' (PDF version) (FRBR), by the International Federation of Library Associations and Institutions, defined the parts of creative works and relationships between these and their published manifestations; and relationships that people and organizations have with the various components. This model may be to complex for our needs, however between the two models we should be able to use some of their concepts and design elements to produce a database for our needs.
The highest level views of FRBR schema is shown in the two diagrams below.
|
|
|---|
Status
SQL Database development is currently suspended. (see Introduction comment above). Although we invite interested people to approach us about continuing this work.
David Wilson 06:43, 27 September 2006 (CEST)
At the last stage of development the database definition was the SQL version, which can be obtained using the subversion web browser.
An entity-relationship diagram and some documentation of that database available, however, these may not be fully up-to-date with the definitive sql version. For an overview of the bibliographic database interaction with the rest of the bibliographic application see the components page.
What needs to be done ?
The main tasks are -
- Complete the design of the database.
- Write core code modules to -
- read records in the bibliographic database and convert them to the xml format used in the document save-package, and append them to the save-package biblio-data.xml file.
- covert records in the document save-package biblio-data.xml format to the database format, and insert them in the database.
- covert records in bibliographic database format to that used in the bibutils package (to allow database export using biblio-utils)
- covert records in format to that used in the bibutils package package to the format used in the bibliographic database (to allow database import using the bibutils package )
- Design the Graphical User Interface (GUI) for maintaining the bibliographic database: adding, modifying, deleting, and searching database records.
- Design the Graphical User Interface (GUI) for searching and selecting bibliographic records to be inserted for citations in Writer documents.
- Build prototype GUI panels for maintaining the bibliographic database: adding, modifying, deleting, and searching database records. (These could built using OOo Database forms and OOo Basic, Java or Python.)
- Build prototype GUI panels for searching and selecting bibliographic records to be inserted for citations in Writer documents. (These could built using OOo Database forms and OOo Basic, Java or Python.)
Comments and Suggestions
Please feel free to add comments and suggestions below
Will the database support keywords ? It does right now, it's covered with the trendy term for the same thing: tags.
Reference Types
There are many different types of references having very specific field requirements for citation. It would be unwise to have the same fields for all those subtypes. Also, recent developments in publishing (e.g. EPUB ahead of print) make traditional referencing difficult. I have posted a similar comment on the brainstorming microformats page, see http://microformats.org/wiki/citation-brainstorming paragraph Concerns not addressed by existing formats and also the various citation examples.
We should therefore:
- first define a set of different basic Reference Types (see also the microformats page)
- expand the fields needed to store the complete references
- create the necessary dependencies/events/links (a plain structure as currently in use, is not optimal, as described later)
- all this should be done in order to be able design a more robust database.
IMPORTANT
I believe that there are some special situations needing special fields/ special management in the DB, not adequately covered yet, in addition to some other issues described below. These are mainly:
- Errata, Comments and Authors Reply and Article Retractions: NOT easily solved with plain bibliographic types (as they may need bidirectional links between the original article and the correspnding Erratum, authors Reply or Retraction Letter)
- other important fields (some needed only sometimes; others more widely useful)
- web URL and a Link to the locally saved file: the two are by no means equivalent; for an extending discussion see http://qa.openoffice.org/issues/show_bug.cgi?id=66354
- hierarhical keyword structure: see http://wiki.services.openoffice.org/wiki/Bib-Keywords
- very specific fields: see discussions below
- EPUB ahead of print
- Patents
- Internet resources
- Conferences
- Book chapters
Basic Reference Types
Articles
- Standard Article: Authors, Title, Journal, Issue, Year, Pages, other (e.g. keywords, url, local file path)
- Article, not-cited: as before + Availability Information (URL, other)
- Other Official Published Material: e.g. Newspaper, ...
- IMPORTANT: Errata
- Erata: one or more Corrections might be posted in various issues of the journal
- this is usually cited as: Orininal Article Citation Data (Correction available in Journal, Issue Nr, Year, Pages) (repeat for more than one correction)
- it is possibly never cited alone
- there should be one table having these data for the Errata and a link to the original article, while the original article contains a link to this Errata
- IMPORTANT: Commentary and Author Reply
- similar to Errata, there might be one or more Comments and Author Replys; this should be stored, too
- however, it is usually not included in the original citation
- it might be used however in a citation, but I do not know exaclty how to cite it optimally (original article should be provided as well)
- IMPORTANT: Article Retraction
- an article may be retracted because of plagiarism or some other flaw
- this should not be used any further in the research
- however, it might be used e.g. for an article on plagiarism or flawed research
- there should be therefore one filed storing this information, too, and a link to:
- the published withdrawal letter (which explains why the article was retracted); I do not know what data to store for such a letter, either
- IMPORTANT: electronic publishing ahead of print (EPUB)
- more and more articles are initially becoming available online, before the published article gets actually printed. In fact an increasing number of journals are now online-only
- How should this be cited?
- Is this changed, after the print version (if there is one) becomes available?
Books
- Book: Author, Title, Publisher, Year, other (pages, url)
- IMPORTANT: Chapter from Book: Author and Title of Chapter, Book Title, Editor/ Authors, Publisher, pages, other data
- we may cite a book as a whole
- or we may cite only one (or more) chapters from a book
- because some data is the same for any one chapter (e.g. Book Title, Editor, Publisher), it would be wise to store the book as a whole in one table and have a different table storing the specific chapters
- and to link the chapters to the book
- see also the following Bibus issue for further information: http://sourceforge.net/tracker/index.php?func=detail&aid=1495638&group_id=110943&atid=657835
Conference Abstract
- Conference Abstract: Author, Title, Conference Title, Location (Town, Country), Date of Conference, other, e.g.:
- the date might be a date range (e.g. 25-27 September 2006), see the following examples
- Peacock JE, Wade JC, Lazarus HM, et al. Ciprofloxacin/piperacillin vs. tobramycin/piperacillin as empiric therapy for fever in neutropenic cancer patients, a randomized, double-blind trial [abstract 373]. In: Program and abstracts of the 37th Interscience Conference on Antimicrob Agents and Chemotherapy (Toronto). Washington, DC: American Society for Microbiology, 1997.
- Gillespie SH, Dickens A. Variation in mutation rate of quinolone resistance in Streptococcus pneumoniae [abstract P06-17A]. In: Abstracts of the 3rd International Symposium on Pneumococci and Pneumococcal Disease (Anchorage, 5-9 May 2002).Washington, DC: American Society of Microbiology, 2002.
Internet Resource
- Internet Resource: Title, Author, URL, Date (accessed on/ last accessed on), other (URL to locally saved version)
- Patents: very specific requirements, like Patent Number, Patent Holder, Issue Date, Country where the patent was issued, possibly some other fields (like short description - what is this patent about)
- see also the Bibus issue http://sourceforge.net/tracker/index.php?func=detail&aid=1490819&group_id=110943&atid=657835
- Others: please expand
Author Problems
There are some situations, where the Author Name is not easy to store. I will give some details below.
- NO Author specified: an article may be published without stating the author, e.g.: CDC Title of Article ..., e.g. all articles from MMWR [1] have no Author indicated, but should be cited as CDC. Article Title. ... (or Centers for Disease Control and Prevention. Title. ...)
- One (or more) Authors plus on behalf of some Study Group: how should this be stored?
- e.g. Work Group on Substance Use Disorders; Kleber HD, Weiss RD, Anton RF, Rounsaville BJ, George TP, Strain EC, Greenfield SF, Ziedonis DM, Kosten TR, Hennessy G, O'Brien CP, Connery HS; American Psychiatric Association Steering Committee on Practice Guidelines; McIntyre JS, Charles SC, Anzia DJ, Nininger JE, Cook IA, Summergrad P, Finnerty MT, Woods SM, Johnson BR, Yager J, Pyles R, Lurie L, Cross CD, Walker RD, Peele R, Barnovitz MA, Gray SH, Shemo JP, Saxena S, Tonnu T, Kunkle R, Albert AB, Fochtmann LJ, Hart C, Regier D. Treatment of patients with substance use disorders, second edition. American Psychiatic Association. Am J Psychiatry. 2006 Aug;163(8 Suppl):5-82. [see on Pubmed, PMID: 16981488]
- a Group Name might be the only information specified in the Author Field
- Group + one (or more) Authors (in this order)
- one (or more) Authors + Group
- we can not store the Group' in the Names Field, because the various formatting styles may break the Group's Name
- although there might be only a group specified as author, the authors might be listed at the end of the article; we may wish to store some of the authors for future correspondence (yet these authors should not be used for formatting the citation)